

Kiến trúc Lakehouse giúp các tổ chức trong lĩnh vực chăm sóc sức khỏe và khoa học đời sống vượt qua những thách thức này bằng một kiến trúc dữ liệu hiện đại, kết hợp giữa chi phí thấp, khả năng mở rộng và tính linh hoạt của Data Lake trên nền tảng đám mây với hiệu năng và khả năng quản trị dữ liệu của Data Warehouse.
Với mô hình Lakehouse, các tổ chức có thể lưu trữ mọi loại dữ liệu và triển khai mọi hình thức phân tích cũng như học máy (ML) trong một môi trường mở.
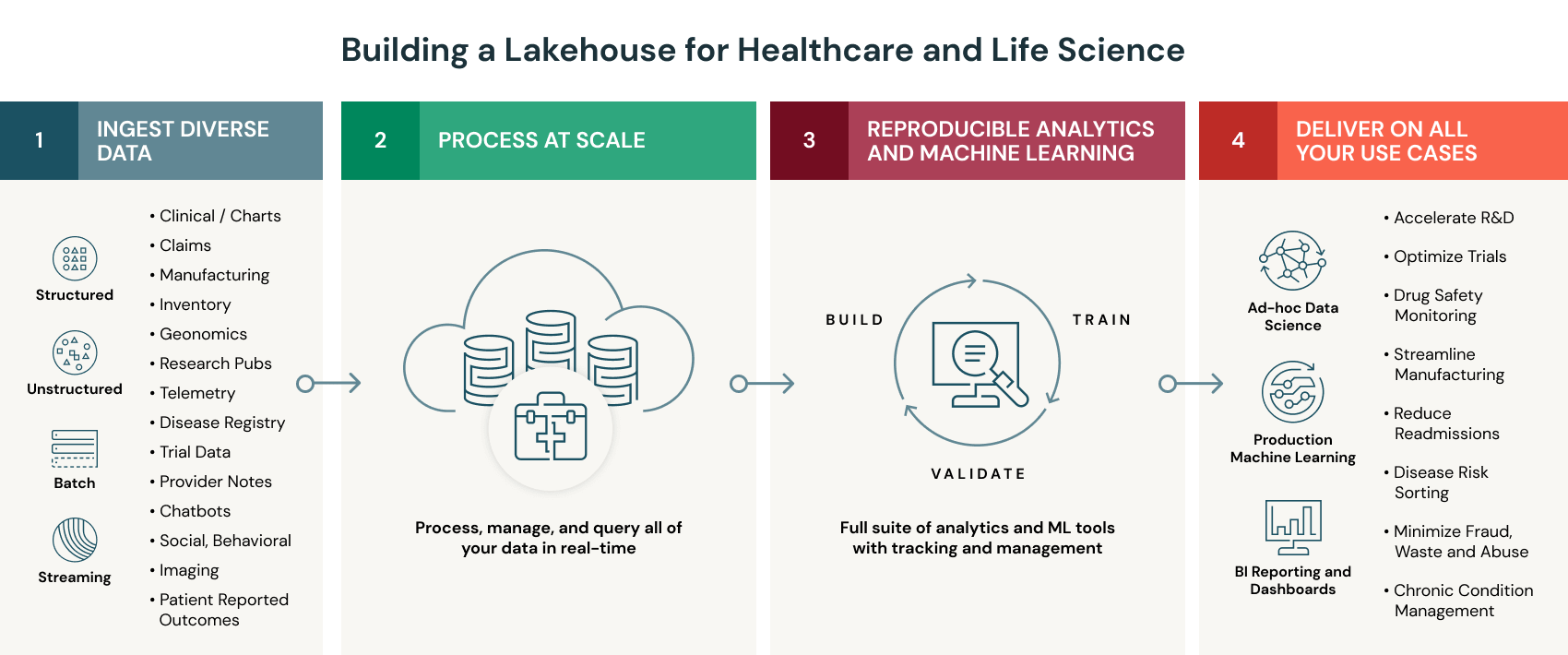
Cụ thể, kiến trúc Lakehouse mang lại những lợi ích sau cho các tổ chức trong lĩnh vực chăm sóc sức khỏe và khoa học đời sống:
- Tổ chức toàn bộ dữ liệu y tế ở quy mô lớn
Trung tâm của nền tảng Databricks Lakehouse là Delta Lake – một lớp quản lý dữ liệu mã nguồn mở, cung cấp độ tin cậy và hiệu năng cao cho Data Lake. Khác với kho dữ liệu truyền thống (Data Warehouse), Delta Lake hỗ trợ mọi loại dữ liệu có cấu trúc và phi cấu trúc.
Để việc tiếp nhận dữ liệu y tế trở nên dễ dàng, Databricks đã xây dựng các đầu nối chuyên biệt cho các loại dữ liệu đặc thù như hồ sơ bệnh án điện tử (EMR) và dữ liệu gen (genomics). Các đầu nối này đi kèm với mô hình dữ liệu theo tiêu chuẩn ngành, tích hợp trong các gói triển khai nhanh (solution accelerators).
Ngoài ra, Delta Lake còn có tối ưu hóa tích hợp sẵn như lưu đệm dữ liệu (caching) và lập chỉ mục (indexing) giúp tăng tốc đáng kể quá trình xử lý dữ liệu. Nhờ những khả năng này, các nhóm có thể tập trung toàn bộ dữ liệu thô tại một nơi duy nhất, sau đó tinh chỉnh để tạo ra cái nhìn toàn diện về sức khỏe bệnh nhân
- Thúc đẩy phân tích và AI cho bệnh nhân
Khi tất cả dữ liệu được tập trung trong kiến trúc Lakehouse, các nhóm có thể dễ dàng xây dựng hệ thống phân tích bệnh nhân mạnh mẽ và các mô hình dự đoán ngay trên nguồn dữ liệu đó.
Để mở rộng khả năng này, Databricks cung cấp không gian làm việc cộng tác (collaborative workspace) với đầy đủ công cụ phân tích và AI, hỗ trợ nhiều ngôn ngữ lập trình như SQL, R, Python và Scala. Điều này giúp các nhóm người dùng đa dạng – từ nhà khoa học dữ liệu, kỹ sư đến chuyên gia tin học lâm sàng – có thể phối hợp để phân tích, mô hình hóa và trực quan hóa dữ liệu y tế một cách hiệu quả.
- Cung cấp thông tin bệnh nhân theo thời gian thực
Lakehouse cung cấp kiến trúc thống nhất cho dữ liệu thời gian thực (streaming) và dữ liệu theo lô (batch) – không cần duy trì hai kiến trúc riêng biệt hoặc lo ngại về độ tin cậy.
Khi triển khai trên nền tảng Databricks, các tổ chức tiếp cận được với nền tảng đám mây gốc (cloud-native) có khả năng tự động mở rộng theo khối lượng công việc. Điều này cho phép tiếp nhận dữ liệu thời gian thực và kết hợp với hàng petabyte dữ liệu lịch sử, để tạo ra thông tin chuyên sâu gần như theo thời gian thực ở quy mô toàn dân số.
- Đảm bảo chất lượng dữ liệu và tuân thủ quy định
Để giải quyết vấn đề độ tin cậy của dữ liệu (data veracity), kiến trúc Lakehouse tích hợp những khả năng mà Data Lake truyền thống còn thiếu như:
- Cưỡng chế lược đồ (schema enforcement)
- Theo dõi lịch sử và kiểm toán (auditing, versioning)
- Kiểm soát truy cập chi tiết (fine-grained access control)
Một lợi ích quan trọng của Lakehouse là khả năng thực hiện cả phân tích và học máy (ML) trên cùng một nguồn dữ liệu tin cậy.
Ngoài ra, Databricks còn cung cấp các chức năng theo dõi và quản lý mô hình ML, giúp các nhóm tái tạo kết quả dễ dàng trên nhiều môi trường và hỗ trợ tuân thủ các tiêu chuẩn pháp lý. Tất cả những khả năng này được cung cấp trong một môi trường phân tích tuân thủ HIPAA (chuẩn bảo mật y tế Hoa Kỳ).
Lakehouse là kiến trúc tối ưu nhất để quản lý dữ liệu chăm sóc sức khỏe và khoa học đời sống.
Khi kết hợp kiến trúc này với năng lực của nền tảng Databricks, các tổ chức có thể triển khai hàng loạt ứng dụng quan trọng, từ nghiên cứu phát triển thuốc đến chương trình quản lý bệnh mãn tính.